

부스팅(boosting, hypothesis boosting)
부스팅은 약한 학습기를 여러개 연결하여 강한 학습기를 만드는 앙상블 방법이다.
AdaBoost(Adaptive boosting)
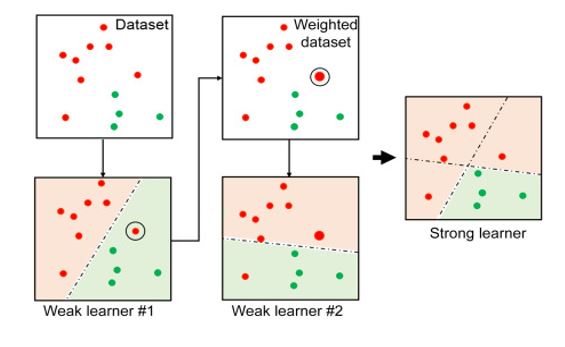
이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높이는 방법.
https://www.analyticsvidhya.com/blog/2022/01/introduction-to-adaboost-for-absolute-beginners/
Introduction to AdaBoost for Absolute Beginners
AdaBoost stands for Adaptive Boosting. It is a statistical classification algorithm that forms a committee of weak classifiers.
www.analyticsvidhya.com
처음 학습한 학습기에서 발생한 오차에 가중치를 부여한다. 이를 이용하여 다시 학습하면, 해당 오차에 예민하게 반응하는 모델이 학습된다. 오차에 가중치를 부여하고 학습하는 과정을 반복함으로써, 여러 예측기를 얻게된다.
이 예측기들을 Ensembling하여 강한 예측기를 제시하는 것이 AdaBoosting의 방식이다.
학습을 연속하여 진행한다는 점에서 경사하강법과 유사하다. 경사하강법은 비용 함수 최소화를 목적으로 모델 파라미터를 조정하지만, AdaBoost는 더 좋은 성능의 예측기를 위해 앙상블에 예측기를 추가하는 방식으로 작동한다.
★ 연속된 학습 기법들은 이전 예측기가 학습, 평가를 마무리하기를 기다려야 하여, 훈련을 병렬화할 수 없다는 단점이 있다. 이 때문에 배깅과 페이스팅만큼 확장성이 높지 않다.
사이킷런의 AdaBoostClassifier를 이용하여 AdaBoost 분류기를 훈련시킬 수 있다. 주로 깊이 1인 Decision Tree를 기본 추정기로 사용한다.
| 파라미터 명 | 설명 |
| base_estimators | 학습에 사용하는 알고리즘 Default = None ( DecisionTreeClassifier(max_depth =1)) |
| n_estimators | 생성할 약한 학습기의 갯수(Default = 50) |
| learning_rate | 학습을 진행할 때 마다 적용하는 학습 |
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
n_estimators =50, learning_rate = 0.5
)
ada_clf.fit(X_train, y_train)
(Overfitting 발생 시, 추정기 수를 줄이거나, 추정기의 규제를 강화하면 해결 가능)
그레이디언트 부스팅(Gradient Boosting)
그레이디언트 부스팅은 앙상블에 이전까지의 오차를 보정하도록 예측기를 순차적으로 추가한다. 반복마다 샘플에 가중치를 부여하는 AdaBoosting과 달리, 새로운 예측기에 잔여 오차(residual error)1 를 학습시키는 방식을 채택한다.
import numpy as np
from sklearn.tree import DecisionTreeRegressor
#잡음이 섞인 2차식 데이터 셋
np.random.seed(42)
X = np.random.rand(100,1) - 0.5
#3x^2에 가우스 잡음 추가
y = 3*X[:,0] **2 +0.05 *np.random.randn(100)
#첫 번째 예측기 학습
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state =42)
tree_reg1.fit(X,y)
#첫 예측에서의 잔차 계산 & 2번째 예측기 학습
y2 = y- tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X,y2)
#3번째 학습 진행
y3 = y- tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X,y3)
#모든 예측 트리의 예측을 더하여 앙상블의 예측을 구한다
X_new = np.array([[-0.4],[0.],[0.5]])
sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
사이킷런의 GradientBoostingRegressor와 Classifier를 이용할 수 있다.
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth = 2, n_estimators=3, learning_rate =1.0)
gbrt.fit(X,y)
Q. GradientBoosting 문제에서 최적의 트리 개수를 찾는 방법은?
A. 마찬가지로 GridSearchCV, RandomizedSearchCV를 활용한 교차 검증을 이용한다. 더 간단한 방법으로 n_iter_no_change 하이퍼 파라미터를 이용한다.
n_iter_no_change 파라미터에 정수값 n을 입력하면, 훈련 중 마지막 n개의 트리가 큰 도움을 주지 않으면(no_change) 학습을 종료하고, 조기에 앙상블한다.
히스토그램 기반 그레이던트 부스팅(histogram-based gradient boosting, HGB)
- 사이킷런의 앙상블 학습 알고리즘
- 그레이디언트 부스팅의 속도를 개선한 버전
- 안정적인 결과와 높은 성능으로 인기가 좋음
- 정형 데이터를 다루는 머신러닝 알고리즘 중 가장 인기가 높음
- 입력 특성을 256개의 구간으로 나누고 그중 하나를 떼어 놓고 누락된 값을 위해 사용
- 입력에 누락된 특성이 있더라도 전처리를 하지 않아도 됨
- 대표적으로 XGBoost 라이브러리와 LightGBM 라이브러리가 있음
- 실제 값과 예측값 사이의 오차값 [본문으로]
'Datascience' 카테고리의 다른 글
| DecisionTree와 Ensembling 실습 : wine 데이터 셋 (1) | 2024.01.07 |
|---|---|
| Ensemble 1: 앙상블 학습과 랜덤 포레스트 (0) | 2024.01.03 |
| Trading Off Precision and Recall(정밀도와 재현률 트레이드 오프) (1) | 2024.01.01 |
| 머신러닝 알고리즘의 성능 평가 지표(Evaluation Metric) (0) | 2023.12.29 |
| Data Preprocessing : Label Encoding * One hot Encoding (0) | 2023.12.29 |