
Skit- Learn의 기반 프레임워크 익히기
지도학습의 주요 두 축인 부류(Classification)과 회귀(Regression)의 다양한 알고리즘을 구현하는 과정에서 fit(), predict()을 활용하여 간단하게 학습과 예측 결과를 반환한다.
Estimator 클래스
Estimator = Classifer(분류 알고리즘 sklearn 클래스) + Regression(회귀 알고리즘 on sklearn)
- 내부에서 각각 fit과 predict를 구현하고 있음
- evaluation 함수(cross_val_score( ) 등), GridSearchCV와 같은 하이퍼 파라미터 튜닝을 지원하는 클래스 등에서 Estimator를 인자로 받음 (함수 내에서 인자로 받은 Estimator의 fit( )과 predict( )를 호출하는 방식)
+ 그외에도 비지도학습(차원 축소, clustering, Feature Extraction) 등을 구현한 클래스에서도 fit( ), predict( )를 정의하고 있다. (단 fit( )는 학습과정이 아닌, 변환을 위해 데이터를 조절하는 방식으로 작동)
sklearn 주요 모듈
- 예제 데이터 = sklearn.dataset
- 피처 처리
sklearn.preprocessing : 데이터 전처리에 필요한 다양한 가공 기능을 담고 있는 모듈
(문자열을 숫자형 코드 값으로 인코딩(get_dummies와 유사), 정규화, 스케일링 등)
sklearn.feature_selection : 알고리즘에 큰 영향을 미치는 피처를 우선순위대로 셀렉션 작업을 수행하는 다양한 기능 제공
sklearn.feature_extraction : 피처처리
Model Selection 모듈 소개
▶ train_test_split( )
sklearn.model_selection.train_test_split( )의 parameters
- test_size : 전체 데이터에서 테스트 데이터 세트의 크기 결정 (default = 0.25)
- train_size : train data set의 크기
- shuffle : 데이터를 분리하기 전에 데이터를 미리 섞을지를 결정 (default = True)
- random_state
- train_test_split( )을 통한 데이터 분리 후에도, overfitting의 문제를 격을 수 있음
→ 이를 해결하기 위한 방법 중 하나가 K-Fold 교차 검증(K-Fold cross Validation)이 대표적

전체 training data set = Fold1 + Fold2 + ... + FoldK 로 분할시키고, 각각의 학습 후 퍼포먼스를 평균적으로 평가함
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
iris = load_iris()
features = iris.data
label = iris.target
dt_clf = DecisionTreeClassifier( )
#5개의 폴드 세트로 분리하는 KFold 객체와 폴드 세트 별 정확도를 담을 리스트 객체를 생성
kfold = KFold(n_splits =5)
cv_accuracy = []
n_iter = 0
#KFold 객체의 split( )를 호출하면 폴드 별 학습용, 검증용 테스트의 로우 인덱스를 arrray로 변환
for train_index, test_index in kfold.split(features):
#kfold.split()으로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터를 추출
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
#학습 & 예측
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
n_iter += 1
#반복마다 정확도 측정
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
- Stratified K 폴드
▶ 불균형한(imbalanced) 분포도를 가진 레이블(결정 클래스) 데이터 집합을 위한 K Fold 방식
★ 원본 데이터가 가지는 값의 분포를 생성한 데이터 폴드에 적용하는 방식 ( 데이터의 남녀 성비 와 Fold의 남녀 성비 유사)
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_split = 3)
n_iter = 0
for train_index, test_index in skf.split(iris_df, iris_df['label']):
n_iter += 1
label_train = iris_df['label'].iloc[train_index]
label_test = iris_df['label'].iloc[test_index]
print('## 교차 검증: {0}'.format(n_iter))
print('학습 레이블 데이터 분포:\n', label_train.value_counts())
print('검증 레이블 데이터 분포:\n', label_train.value_counts())
#skf 객체를 생성한 StratifiedKFold 메소드로 생성한 폴드의 분포를 비교
#유사한 비율 가진 유의미한 학습, 검증 폴드 구성 + 불균형한 데이터 셋에서 유의미함
º GridSearchCV - 교차 검증과 최적 하이퍼 파라미터 튜닝 동시에 진행
Hyper Parameter
하이퍼파라미터는 데이터 과학자가 기계 학습 모델 훈련을 관리하는 데 사용하는 외부 구성 변수입니다.
때때로 모델 하이퍼파라미터라고 부르며, 하이퍼파라미터는 모델을 훈련하기 전에 수동으로 설정됩니다.
하이퍼파라미터는 파라미터와는 다르며, 데이터 과학자에 의해 설정되는 것이 아닌 학습 프로세스 중에 자동으로 파생되는 내부 파라미터입니다.
하이퍼파라미터의 예로는 신경망의 노드 및 계층 수와 의사 결정 트리의 분기 수가 있습니다. 하이퍼파라미터는 모델 아키텍처, 학습 속도 및 모델 복잡성과 같은 주요 기능을 결정합니다.
신경망에서의 노드 계층, Decision Tree의 depth 등 모델의 형태를 결정할 수 있는 Hyper Parameter
하이퍼 파라미터는 머신러닝 알고리즘을 구성하는 주요 구성 요소이다. 이를 조정함으로써 알고리즘의 예측 성능을 개선할 수 있다.
Skit-learn의 GridSearchCV API를 활용하면 Classifier나 Regressor와 같은 알고리즘에 사용되는 하이퍼 파라미터를 순차적으로 입력하면서 편리하게 최적의 파라미터를 도출하는 방안을 제공한다.
▶ Grid(격자)가 연상되는 형태로 미리 선정한 parameter 집합에서 하나씩 대입 후 최적의 성능으로 향하는 parameter 선정
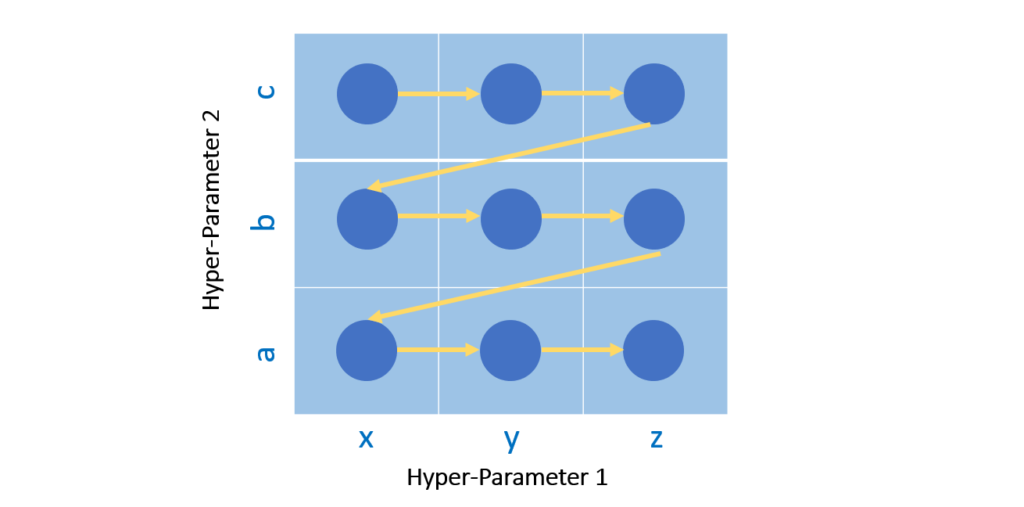
https://medium.com/@silvershine1st/hyperparameter-optimization-methods-6f4ffbec2668
Hyperparameter Optimization Methods
It is a challenging task to choose the best hyperparameters for our model. We can accomplish that using GridSearchCV or RandomizedSearchCV…
medium.com
GridSearchCV의 parameter
| estimator | classifer, regressor, pipeline등이 사용 |
| param_grid | Hyper parameter 튜닝에 사용할 값들을 포함하고 있는 딕셔너리 (예시: param = {'max_depth' : [1,2,4], 'min_samples_split' :[1,2]}) |
| scoring | 에측 성능 평가할 지표 지정 |
| cv | 교차 검증을 위해 분할되는 학습/테스트 세트의 개수를 지정 |
| refit | 가장 최적의 하이퍼 파라미터를 찾은 후, 이를 estimator 객체를 해당 하이퍼 파라미터를 통해 학습함(default = True) |
GridSerach 예제
모형 최적화 — 데이터 사이언스 스쿨 (datascienceschool.net)
모형 최적화 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
'Datascience' 카테고리의 다른 글
| Ensemble 2: AdaBoosting과 GradientBoosting (0) | 2024.01.06 |
|---|---|
| Ensemble 1: 앙상블 학습과 랜덤 포레스트 (0) | 2024.01.03 |
| Trading Off Precision and Recall(정밀도와 재현률 트레이드 오프) (1) | 2024.01.01 |
| 머신러닝 알고리즘의 성능 평가 지표(Evaluation Metric) (0) | 2023.12.29 |
| Data Preprocessing : Label Encoding * One hot Encoding (0) | 2023.12.29 |